
상황
기존에는 크루 메인뷰에서 단순히 코치 목록을 조회했으나, 사용자 피드백을 받는 과정에서 코치가 면담가능한 일정이 등록되어 있는지 메인뷰에서 알고 싶다는 피드백이 들어왔다.
코치를 매번 클릭해서 등록된 일정이 있는지 찾는 과정이 번거로웠던 것 같다.
그래서 아래와 같이 예약가능한 코치일 경우 오른쪽 상단에 초록점을 통해 표시하도록 만들기로 했다.

문제점
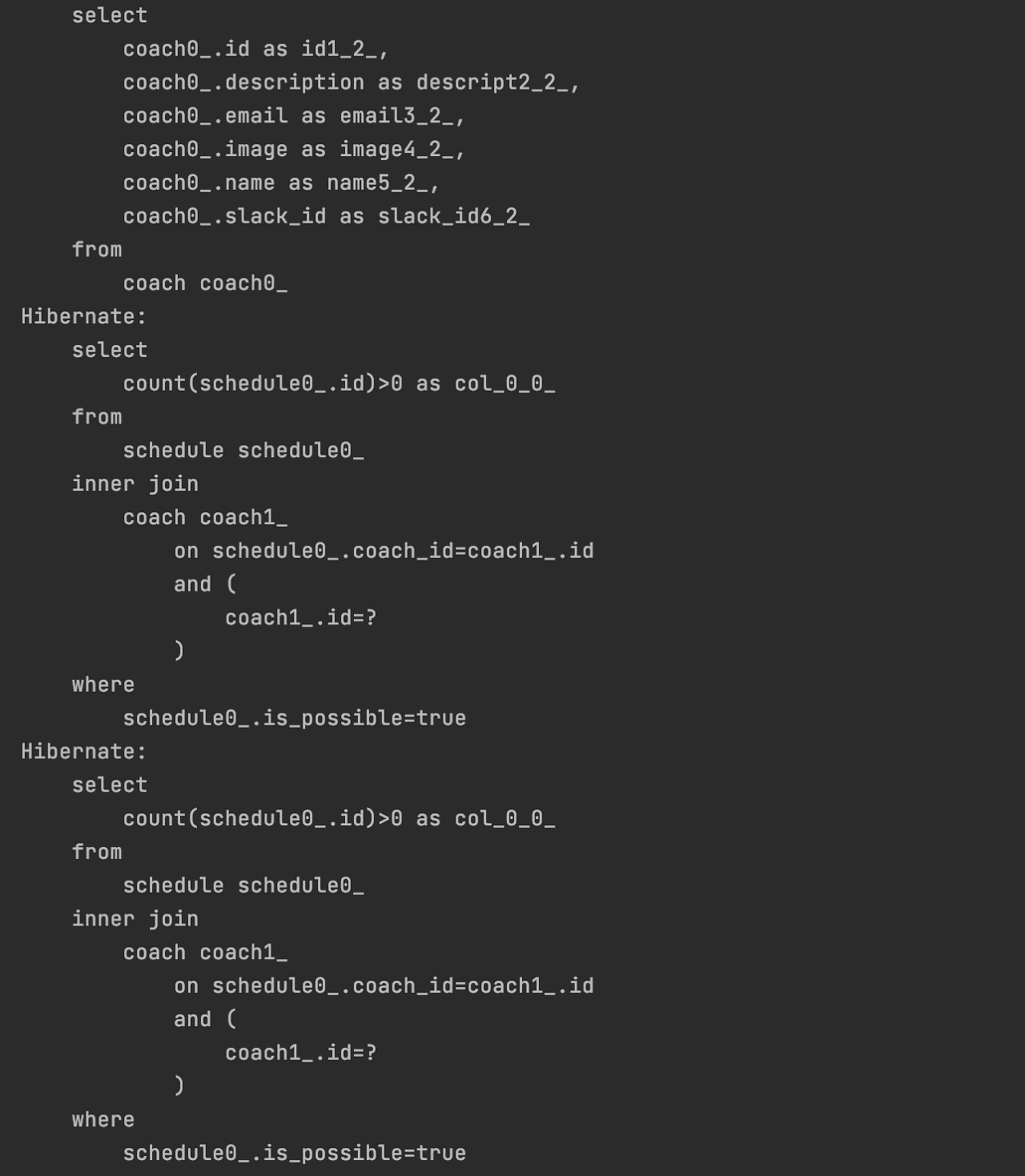
코치가 한명일 때는 문제가 없었지만, 코치 수가 늘어남에 따라 coach_id에 해당하는 schedule 테이블을 조회하는 쿼리가 비례해서 나가는 상황이 발생했다.
즉, 코치수에 비례해 쿼리가 하나씩 추가로 발생하는 1+N 문제가 발생한 것이다.
코드
@Transactional(readOnly = true)
public List<CoachFindResponse> findAll() {
List<CoachFindResponse> response = new LinkedList<>();
List<Coach> coaches = coachRepository.findAll();
for (Coach coach : coaches) {
boolean isPossible = scheduleRepository.existsIsPossibleByCoachId(coach.getId());
response.add(new CoachFindResponse(coach, isPossible));
}
return response;
}SQL 쿼리문
해결방안
네이티브 SQL 사용
1+N 문제를 해결하는 방법에는 3가지가 있다.
- 페치조인
- @BactchSize
- 네이티브 SQL
우리는 서브쿼리를 이용할 수 밖에 없어, 3번째 방법인 네이티브 SQL 방식으로 문제를 해결했다.
네이티브 SQL을 사용할 수 밖에 없었던 이유
네이티브 SQL은 JPQL이 자동으로 생성하는 SQL을 수동으로 직접 작성하는 것이다.
따라서, JPA가 제공하는 기능 대부분을 그대로 사용할 수 있다.
그러나 네이티브 SQL은 관리하기 쉽지 않고 컴파일 시점에 문법을 체크할 수 없어 유지보수하기 어렵다.
더구나 특정 데이터베이스에 종속적인 쿼리가 증가해 이식성이 떨어진다는 단점도 존재한다.
이러한 단점에도 불구하고 우리가 네이티브 SQL을 사용할 수 밖에 없었던 이유는 페치조인이나 @BatchSize로는 해결할 수 없었기 때문이다.
페치조인이나 @BatchSize는 기본적으로 엔티티 내 연관관계에 속한 엔티티를 한번에 들고오는 방법이다.
그러나 우리가 필요했던 것은 조건에 맞는 스케줄이 존재하는지 여부이다!
단순히 true, false를 위해 모든 엔티티를 들고오는건 굉장히 비효율적이라고 생각했다.
서브쿼리를 JPQL로 작성하는 방법도 고려했었으나, JPQL은 WHERE, HAVING절에서만 쓸 수 있기 떄문에 사용하지 못했다.
스칼라 서브쿼리
참고로 이렇게 SELECT 절에 사용하는 서브쿼리를 스칼라 서브쿼리라고 한다.
스칼라 서브쿼리는 반드시 하나의 행(Row)만 반환되어야 한다.
Repository
Named Native SQL을 사용했다.
public interface CoachRepository extends JpaRepository<Coach, Long> {
@Query(name = "findCoaches", nativeQuery = true)
List<CoachWithPossible> findCoaches();
}Domain
@NamedNativeQuery로 쿼리를 선언하고, 결과값을 매핑할 때 @SqlResultSetMapping을 사용해서 도메인이 조금 지저분해졌다.
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Getter
@Entity
@SqlResultSetMapping(
name = "CoachWithPossibleMapping",
classes = @ConstructorResult(
targetClass = CoachWithPossible.class,
columns = {
@ColumnResult(name = "id", type = Long.class),
@ColumnResult(name = "name", type = String.class),
@ColumnResult(name = "description", type = String.class),
@ColumnResult(name = "image", type = String.class),
@ColumnResult(name = "possible", type = Boolean.class),
}
)
)
@NamedNativeQuery(
name = "findCoaches",
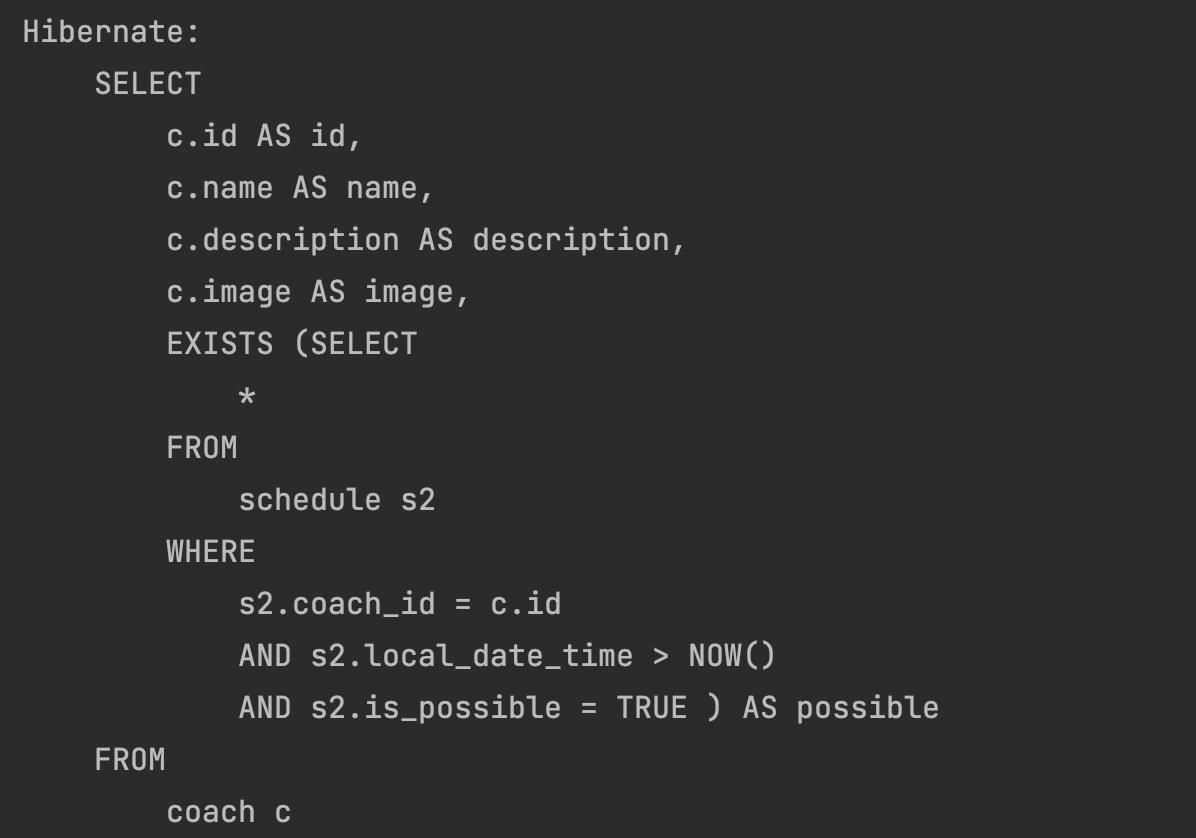
query = "SELECT c.id AS id, c.name AS name, c.description AS description, c.image AS image, EXISTS ("
+ "SELECT * FROM schedule s2 WHERE s2.coach_id = c.id AND s2.local_date_time > NOW() AND s2.is_possible = TRUE ) AS possible "
+ "FROM coach c",
resultSetMapping = "CoachWithPossibleMapping")
public class Coach {
//(중략)
}Service
@Transactional(readOnly = true)
public List<CoachFindResponse> findAll() {
List<CoachWithIsPossible> coaches = scheduleRepository.findAllCoachWithIsPossible();
return coaches.stream()
.map(CoachFindResponse::new)
.collect(Collectors.toList());
}SQL 쿼리문
단 하나의 쿼리만 발생하는 것을 눈으로 확인할 수 있었다.
추가로 생각해볼 점
1) 유지보수의 관점
SQL문을 그대로 사용하다보니 가독성이 떨어지고 컴파일 타임에 SQL문을 확인할 수 없다는 단점이 발생했다.
Querydsl로 이 문제를 해결할 수 없을까 고민해봐야겠다.
2) 역정규화
1+N 문제가 발생했던 근본적인 원인은 조회시 필요한 데이터가 Coach와 Schedule에 분산되어 있었기 때문이다.
지금은 조건에 맞는 스케줄이 존재하는지(isPossible)에 대한 데이터만 추가로 필요했지만,
해당 코치가 지금까지 완료한 면담수와 같이 더 많은 데이터가 필요하다면 이를 위한 테이블을 만드는 것을 고려해보는 것이 좋다.
이처럼 기존에 한곳에서 저장하던 데이터를 분산하여 DB 성능을 개선하는 전략을 역정규화라고 한다.
출처
'우아한테크코스' 카테고리의 다른 글
| JPA 성능 개선기 4. saveAll() (0) | 2022.10.19 |
|---|---|
| JPA 성능 개선기 3. 페치조인 (0) | 2022.10.19 |
| JPQL을 사용할 때는 join 타입을 꼭 명시하자 (1) | 2022.09.29 |
| JPA 성능 개선기 1. 쿼리 개수 및 시간 로깅 (0) | 2022.09.28 |
| Mysql 쿼리최적화 (2) | 2022.09.25 |